Deliberative Alignment: o3’s Secret Sauce
Overview
OpenAI’s newest o3 model employs a novel training scheme that incentivizes the model to use Chain-of-Though (CoT) reasoning at inference time to navigate complex user requests as helpfully as possible while adhering to an extensive safety specification.
Below, I’ve distilled the core procedure that enables training an LLM to perform CoT at inference time without explicit prompting. While the information below is taken mainly from OpenAI’s report on alignment in o-series models, their general post-training scheme likely follows a similar format.
We’ll take for granted that we have a safety specification available to us that tells us how we should complete prompts for sensitive categories of content, such as requests related to self-harm, extremism, or regulated substances. At training time, we will present this specification to the model and attempt to encode knowledge of this safety specification in its weights. Simultaneously, we will encourage the model to navigate any subtleties in our specification as dexterously as possible to maximize its helpfulness.
Deliberative Alignment proceeds as follows:
- We formulate our safety specification.
- We generate a CoT dataset for Supervised Fine-Tuning.
- We fine-tune our base model.
- We fine-tune our model further using Reinforcement Learning.
Below, we’ll go over steps 2–4 in detail.
Supervised Fine-Tuning (SFT):
The goal of the SFT step is twofold. First, we aim to reinforce the expectation that the model will use a helpful and valid chain of thought to construct its prompt completion. Second, for alignment, we want the model to memorize relevant portions of the safety specifications for our categories of interest (i.e., the categories represented in the SFT data).
To do this, we must first construct a useful, high-quality dataset of examples. Each example will consist of a prompt, CoT, and completion. However, generating many examples of CoT for this dataset would be highly labor-intensive for human annotators. Therefore, the authors instead set up an automated pipeline by which we can generate a set of high-quality (prompt, CoT, completion) tuples with relatively little expense. The key insight here is that we can use language models to both generate and curate the SFT training data.
We first produce a pre-trained base model (that we wish to align) and a reward model (usually another LLM). The base model is given a prompt and instructed to use CoT reasoning to complete the prompt. The base model is provided access to part of the safety specification that is relevant to the current prompt and is given instructions to cite the specification as necessary in its context. After the base model produces a completion, the reward model decides whether the completion should be added to our fine-tuning dataset.

The reward model is provided with the safety specification and is instructed to rate the CoT and final answer for compliance with the safety specification, helpfulness to the user, and overall correctness. For some examples, there is some metadata available that may include labels produced by humans or other models that inform us whether we ought to complete this request, partially fulfill it, or outright refuse this completion based on the content of the prompt — the reward model is provided this rating in its context for those examples where it is available. To ensure the robustness of our labels, the reward model rates each individual completion multiple times, and the minimum score across these ratings is taken as the final score for that data point.
Examples that achieve a reward below a user-defined threshold are discarded, and the remainder are stored as data points for the SFT step. Once this process is complete, we will have generated a full dataset of high-quality (prompt, CoT, completion) tuples for fine-tuning. The selective use of externally produced labels from either humans or AI allows us to subtly steer the reward model’s decision-making without excessive label noise. While, in principle, having an entirely handmade dataset of CoT examples would improve our resulting model’s performance, in practice, this technique works exceptionally well in aligning models at a fraction of the cost.
Once we have the SFT dataset, we perform a standard fine-tuning procedure on our base model. However, from now on the base model will not be provided the safety specification. This is intended to teach the model to internalize relevant parts of the safety specification for categories of interest even when they are not explicitly provided.
Reinforcement Learning (RL):
After SFT, we apply reinforcement learning to align our model further. In this step, we use our reward model to rate the base model’s output again. In particular, the reward model is provided the safety specification and any relevant metadata, if available, and is once again asked to produce a rating based on compliance, helpfulness, and correctness. However, in this stage, the base model’s CoT is not visible to the reward model; it can only see the prompt completion. The authors note that this is to prevent the model from learning to generate deceptive CoT while actually being non-compliant.

Discussion
Notably, the RL step described above has only been applied to o1 and o3, whereas previous o-series models were only trained using the abovementioned SFT procedure. The authors conduct several ablation studies to measure the contribution of the SFT and RL steps to the final model’s performance. Interestingly, using just SFT gives roughly similar results to using just RL in most evaluations. Meanwhile, combining them outperforms each of them individually.
While the authors present these results as if SFT and RL individually provide “intermediate” performance compared to using them jointly, the evaluation numbers vary quite a bit depending on the benchmark. For instance, the improvement in alignment is relatively small when we consider “refusal” benchmarks, even showing slight degradation in “overrefusal” performance. In contrast, for very nuanced tasks that require care in formulating a response, such as self-harm related completions, applying both SFT and RL seems to improve scores more — though it’s worth mentioning that the model tends to perform poorly on these in general, so a more considerable relative improvement still does not translate to exceptional performance in the wild.
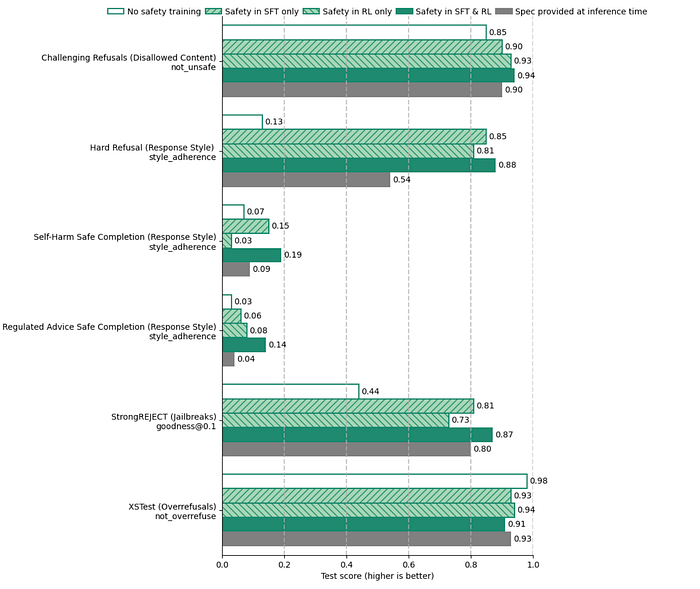
That said, these results would likely vary a lot if we consider the amount of compute we allot for our model. Though compute-intensive, the RL step is relatively easy to orchestrate, and the SFT step can be run as long as we desire once we have curated a dataset. Given that the authors report a trend of increasing performance given more inference-time compute and that LLMs generally seem to benefit from increased train-time compute, it seems reasonable to conclude that scaling this methodology further will continue to enhance performance.
Comparison to Constitutional AI (CAI):
Anthropic’s Claude series models employ Constitutional AI or RLAIF for alignment training. In this paradigm, we also use another LLM to guide the alignment of our base model. At a high level, CAI uses a “judge” model that is provided a set of governing principles for the ideal model’s behavior (a “constitution”) and rates the base model’s completions on the alignment dataset in the context of these alignment principles. Similar to Deliberative Alignment (DA), we use the judge and base model to produce a dataset of (response, critique, revision) tuples which are subsequently used for SFT. Following this, Anthropic constructs a preference model which is fine-tuned on preference data produced by the judge model. This preference model is used to tune the base model in a manner similar to RLHF (hence, RLAIF).
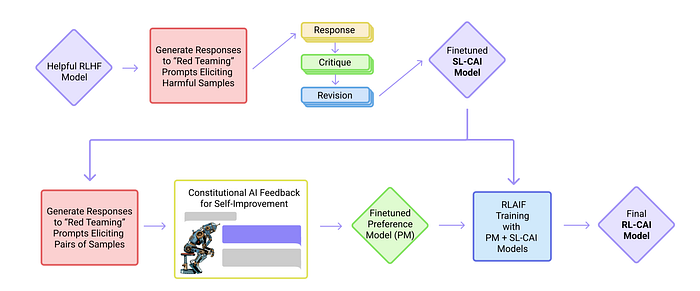
Both DA and CAI are similar in their combination of SFT and RL (which is now relatively standard in the industry) and their use of LLMs to reduce the cost of producing large datasets for alignment training. Indeed, the “critique” in CAI fulfills the same role as the “CoT” in DA. The critical difference between these two approaches is that in CAI, the base model never directly interacts with or encodes the safety specification. In contrast, DA actively encourages the model to memorize portions of the safety specification into its weights using optimization pressure.
The fact that DA also makes explicit the expectation that the model should use CoT reasoning during inference is also a significant difference, but it remains to be seen whether this choice contributes to any significant difference in downstream performance. While initial benchmark results from models like o3 seem positive, and evidence indicates that scaling test-time compute allocations tends to improve model performance, I would be wary of taking these results at face value. There are still very pertinent issues, such as data leakage, that make evaluating LLMs in a rigorous, unbiased manner extremely difficult. As such, it's hard to be confident in what these benchmark results tell us.
The biggest takeaway is that Deliberative Alignment is another step towards making the training and alignment of larger models scalable, less labor-intensive, and more effective. Even as the size of datasets required to take advantage of extreme-scale models grows ever larger, we are formulating tools that allow us to circumvent the practical limitations of curating data at scale.
References
[1] Deliberative Alignment: Reasoning Enables Safer Language Models (https://arxiv.org/abs/2412.16339)
[2] Constitutional AI: Harmlessness from AI Feedback (https://arxiv.org/abs/2212.08073)
